Although object-oriented programming has shifted attention from functions and toward objects, functions nonetheless remain a central component of any program. Today you will learn
A function is, in effect, a subprogram that can act on data and return a value. Every C++ program has at least one function, main(). When your program starts, main() is called automatically. main() might call other functions, some of which might call still others.
Each function has its own name, and when that name is encountered, the execution
of the program branches to the body of that function. When the function returns,
execution resumes on the next line of the calling function. This flow is illustrated
in Figure 5.1.
Figure
5.1. Illusrtation
of flow
When a program calls a function, execution switches to the function and then resumes at the line after the function call. Well-designed functions perform a specific and easily understood task. Complicated tasks should be broken down into multiple functions, and then each can be called in turn.
Functions come in two varieties: user-defined and built-in. Built-in functions are part of your compiler package--they are supplied by the manufacturer for your use.
Using functions in your program requires that you first declare the function and that you then define the function. The declaration tells the compiler the name, return type, and parameters of the function. The definition tells the compiler how the function works. No function can be called from any other function that hasn't first been declared. The declaration of a function is called its prototype.
There are three ways to declare a function:
Although you can define the function before using it, and thus avoid the necessity of creating a function prototype, this is not good programming practice for three reasons.
First, it is a bad idea to require that functions appear in a file in a particular order. Doing so makes it hard to maintain the program as requirements change.
Second, it is possible that function A() needs to be able to call function B(), but function B() also needs to be able to call function A() under some circumstances. It is not possible to define function A() before you define function B() and also to define function B() before you define function A(), so at least one of them must be declared in any case.
Third, function prototypes are a good and powerful debugging technique. If your prototype declares that your function takes a particular set of parameters, or that it returns a particular type of value, and then your function does not match the prototype, the compiler can flag your error instead of waiting for it to show itself when you run the program.
Many of the built-in functions you use will have their function prototypes already written in the files you include in your program by using #include. For functions you write yourself, you must include the prototype.
The function prototype is a statement, which means it ends with a semicolon. It consists of the function's return type, name, and parameter list.
The parameter list is a list of all the parameters and their types, separated
by commas. Figure 5.2 illustrates the parts of the function prototype.
Figure
5.2. Parts of a function prototype.
The function prototype and the function definition must agree exactly about the return
type, the name, and the parameter list. If they do not agree, you will get a compile-time
error. Note, however, that the function prototype does not need to contain the names
of the parameters, just their types. A prototype that looks like this is perfectly
legal:
long Area(int, int);
This prototype declares a function named Area() that returns a long and that has two parameters, both integers. Although this is legal, it is not a good idea. Adding parameter names makes your prototype clearer. The same function with named parameters might be
long Area(int length, int width);
It is now obvious what this function does and what the parameters are.
Note that all functions have a return type. If none is explicitly stated, the return type defaults to int. Your programs will be easier to understand, however, if you explicitly declare the return type of every function, including main(). Listing 5.1 demonstrates a program that includes a function prototype for the Area() function.
Listing 5.1. A function declaration and the definition and use of that function.
1: // Listing 5.1 - demonstrates the use of function prototypes
2:
3: typedef unsigned short USHORT;
4: #include <iostream.h>
5: USHORT FindArea(USHORT length, USHORT width); //function prototype
6:
7: int main()
8: {
9: USHORT lengthOfYard;
10: USHORT widthOfYard;
11: USHORT areaOfYard;
12:
13: cout << "\nHow wide is your yard? ";
14: cin >> widthOfYard;
15: cout << "\nHow long is your yard? ";
16: cin >> lengthOfYard;
17:
18: areaOfYard= FindArea(lengthOfYard,widthOfYard);
19:
20: cout << "\nYour yard is ";
21: cout << areaOfYard;
22: cout << " square feet\n\n";
23: return 0;
24: }
25:
26: USHORT FindArea(USHORT l, USHORT w)
27: {
28: return l * w;
29: }
Output: How wide is your yard? 100
How long is your yard? 200
Your yard is 20000 square feet
Analysis: The prototype for the FindArea()
function is on line 5. Compare the prototype with the definition of the function
on line 26. Note that the name, the return type, and the parameter types are the
same. If they were different, a compiler error would have been generated. In fact,
the only required difference is that the function prototype ends with a semicolon
and has no body.
Also note that the parameter names in the prototype are length and width,
but the parameter names in the definition are l and w. As discussed,
the names in the prototype are not used; they are there as information to the programmer.
When they are included, they should match the implementation when possible. This
is a matter of good programming style and reduces confusion, but it is not required,
as you see here.
The arguments are passed in to the function in the order in which they are declared and defined, but there is no matching of the names. Had you passed in widthOfYard, followed by lengthOfYard, the FindArea() function would have used the value in widthOfYard for length and lengthOfYard for width. The body of the function is always enclosed in braces, even when it consists of only one statement, as in this case.
The definition of a function consists of the function header and its body. The header is exactly like the function prototype, except that the parameters must be named, and there is no terminating semicolon.
The body of the function is a set of statements enclosed in braces. Figure 5.3 shows the header and body of a function.
Figure 5.3. The header and body of a function.
Function Prototype Syntax
return_type function_name ( [type [parameterName]]...);
Function Definition Syntax
return_type function_name ( [type parameterName]...)
{
statements;
}
A function prototype tells the compiler the return type, name, and parameter list. Func-tions are not required to have parameters, and if they do, the prototype is not required to list their names, only their types. A prototype always ends with a semicolon (;). A function definition must agree in return type and parameter list with its prototype. It must provide names for all the parameters, and the body of the function definition must be surrounded by braces. All statements within the body of the function must be terminated with semicolons, but the function itself is not ended with a semicolon; it ends with a closing brace. If the function returns a value, it should end with a return statement, although return statements can legally appear anywhere in the body of the function. Every function has a return type. If one is not explicitly designated, the return type will be int. Be sure to give every function an explicit return type. If a function does not return a value, its return type will be void.
long FindArea(long length, long width); // returns long, has two parameters void PrintMessage(int messageNumber); // returns void, has one parameter int GetChoice(); // returns int, has no parameters
BadFunction(); // returns int, has no parameters
long Area(long l, long w)
{
return l * w;
}
void PrintMessage(int whichMsg)
{
if (whichMsg == 0)
cout << "Hello.\n";
if (whichMsg == 1)
cout << "Goodbye.\n";
if (whichMsg > 1)
cout << "I'm confused.\n";
}
When you call a function, execution begins with the first statement after the opening brace ({). Branching can be accomplished by using the if statement (and related statements that will be discussed on Day 7, "More Program Flow"). Functions can also call other functions and can even call themselves (see the section "Recursion," later in this chapter).
Not only can you pass in variables to the function, but you also can declare variables within the body of the function. This is done using local variables, so named because they exist only locally within the function itself. When the function returns, the local variables are no longer available.
Local variables are defined like any other variables. The parameters passed in to the function are also considered local variables and can be used exactly as if they had been defined within the body of the function. Listing 5.2 is an example of using parameters and locally defined variables within a function.
Listing 5.2. The use of local variables and parameters.
1: #include <iostream.h>
2:
3: float Convert(float);
4: int main()
5: {
6: float TempFer;
7: float TempCel;
8:
9: cout << "Please enter the temperature in Fahrenheit: ";
10: cin >> TempFer;
11: TempCel = Convert(TempFer);
12: cout << "\nHere's the temperature in Celsius: ";
13: cout << TempCel << endl;
14: return 0;
15: }
16:
17: float Convert(float TempFer)
18: {
19: float TempCel;
20: TempCel = ((TempFer - 32) * 5) / 9;
21: return TempCel;
22: }
Output: Please enter the temperature in Fahrenheit: 212
Here's the temperature in Celsius: 100
Please enter the temperature in Fahrenheit: 32
Here's the temperature in Celsius: 0
Please enter the temperature in Fahrenheit: 85
Here's the temperature in Celsius: 29.4444
Analysis: On lines 6 and 7, two float
variables are declared, one to hold the temperature in Fahrenheit and one to hold
the temperature in degrees Celsius. The user is prompted to enter a Fahrenheit temperature
on line 9, and that value is passed to the function Convert().
Execution jumps to the first line of the function Convert() on line 19,
where a local variable, also named TempCel, is declared. Note that this
local variable is not the same as the variable TempCel on line 7. This variable
exists only within the function Convert(). The value passed as a parameter,
TempFer, is also just a local copy of the variable passed in by main().
This function could have named the parameter FerTemp and the local variable CelTemp, and the program would work equally well. You can enter these names again and recompile the program to see this work.
The local function variable TempCel is assigned the value that results
from subtracting 32 from the parameter TempFer, multiplying by 5, and then
dividing by 9. This value is then returned as the return value of the function, and
on line 11 it is assigned to the variable TempCel in the main()
function. The value is printed on line 13.
The program is run three times. The first time, the value 212 is passed
in to ensure that the boiling point of water in degrees Fahrenheit (212) generates
the correct answer in degrees Celsius (100). The second test is the freezing point
of water. The third test is a random number chosen to generate a fractional result.
As an exercise, try entering the program again with other variable names as illustrated here:
1: #include <iostream.h>
2:
3: float Convert(float);
4: int main()
5: {
6: float TempFer;
7: float TempCel;
8:
9: cout << "Please enter the temperature in Fahrenheit: ";
10: cin >> TempFer;
11: TempCel = Convert(TempFer);
12: cout << "\nHere's the temperature in Celsius: ";
13: cout << TempCel << endl;
14: }
15:
16: float Convert(float Fer)
17: {
18: float Cel;
19: Cel = ((Fer - 32) * 5) / 9;
20: return Cel;
21: }
You should get the same results.
Normally scope is obvious, but there are some tricky exceptions. Currently, variables declared within the header of a for loop (for int i = 0; i<SomeValue; i++) are scoped to the block in which the for loop is created, but there is talk of changing this in the official C++ standard.
None of this matters very much if you are careful not to reuse your variable names within any given function.
Variables defined outside of any function have global scope and thus are available from any function in the program, including main().
Local variables with the same name as global variables do not change the global variables. A local variable with the same name as a global variable hides the global variable, however. If a function has a variable with the same name as a global variable, the name refers to the local variable--not the global--when used within the function. Listing 5.3 illustrates these points.
Listing 5.3. Demonstrating global and local variables.
1: #include <iostream.h>
2: void myFunction(); // prototype
3:
4: int x = 5, y = 7; // global variables
5: int main()
6: {
7:
8: cout << "x from main: " << x << "\n";
9: cout << "y from main: " << y << "\n\n";
10: myFunction();
11: cout << "Back from myFunction!\n\n";
12: cout << "x from main: " << x << "\n";
13: cout << "y from main: " << y << "\n";
14: return 0;
15: }
16:
17: void myFunction()
18: {
19: int y = 10;
20:
21: cout << "x from myFunction: " << x << "\n";
22: cout << "y from myFunction: " << y << "\n\n";
23: }
Output: x from main: 5
y from main: 7
x from myFunction: 5
y from myFunction: 10
Back from myFunction!
x from main: 5
y from main: 7
Analysis: This simple program illustrates
a few key, and potentially confusing, points about local and global variables. On
line 1, two global variables, x and y, are declared. The global
variable x is initialized with the value 5, and the global variable
y is initialized with the value 7.
On lines 8 and 9 in the function main(), these values are printed to the
screen. Note that the function main() defines neither variable; because
they are global, they are already available to main().
When myFunction() is called on line 10, program execution passes to line 18, and a local variable, y, is defined and initialized with the value 10. On line 21, myFunction() prints the value of the variable x, and the global variable x is used, just as it was in main(). On line 22, however, when the variable name y is used, the local variable y is used, hiding the global variable with the same name.
The function call ends, and control returns to main(), which again prints the values in the global variables. Note that the global variable y was totally unaffected by the value assigned to myFunction()'s local y variable.
In C++, global variables are legal, but they are almost never used. C++ grew out of C, and in C global variables are a dangerous but necessary tool. They are necessary because there are times when the programmer needs to make data available to many functions and he does not want to pass that data as a parameter from function to function.
Globals are dangerous because they are shared data, and one function can change a global variable in a way that is invisible to another function. This can and does create bugs that are very difficult to find.
On Day 14, "Special Classes and Functions," you'll see a powerful alternative to global variables that C++ offers, but that is unavailable in C.
Variables declared within the function are said to have "local scope." That means, as discussed, that they are visible and usable only within the function in which they are defined. In fact, in C++ you can define variables anywhere within the function, not just at its top. The scope of the variable is the block in which it is defined. Thus, if you define a variable inside a set of braces within the function, that variable is available only within that block. Listing 5.4 illustrates this idea.
Listing 5.4. Variables scoped within a block.
1: // Listing 5.4 - demonstrates variables
2: // scoped within a block
3:
4: #include <iostream.h>
5:
6: void myFunc();
7:
8: int main()
9: {
10: int x = 5;
11: cout << "\nIn main x is: " << x;
12:
13: myFunc();
14:
15: cout << "\nBack in main, x is: " << x;
16: return 0;
17: }
18:
19: void myFunc()
20: {
21:
22: int x = 8;
23: cout << "\nIn myFunc, local x: " << x << endl;
24:
25: {
26: cout << "\nIn block in myFunc, x is: " << x;
27:
28: int x = 9;
29:
30: cout << "\nVery local x: " << x;
31: }
32:
33: cout << "\nOut of block, in myFunc, x: " << x << endl;
34: }
Output: In main x is: 5
In myFunc, local x: 8
In block in myFunc, x is: 8
Very local x: 9
Out of block, in myFunc, x: 8
Back in main, x is: 5
Analysis: This program begins with
the initialization of a local variable, x, on line 10, in main().
The printout on line 11 verifies that x was initialized with the value 5.
MyFunc() is called, and a local variable, also named x, is initialized
with the value 8 on line 22. Its value is printed on line 23.
A block is started on line 25, and the variable x from the function is printed again on line 26. A new variable also named x, but local to the block, is created on line 28 and initialized with the value 9.
The value of the newest variable x is printed on line 30. The local block ends on line 31, and the variable created on line 28 goes "out of scope" and is no longer visible.
When x is printed on line 33, it is the x that was declared on line 22. This x was unaffected by the x that was defined on line 28; its value is still 8.
On line 34, MyFunc() goes out of scope, and its local variable x becomes unavailable. Execution returns to line 15, and the value of the local variable x, which was created on line 10, is printed. It was unaffected by either of the variables defined in MyFunc().
Needless to say, this program would be far less confusing if these three variables were given unique names!
There is virtually no limit to the number or types of statements that can be in a function body. Although you can't define another function from within a function, you can call a function, and of course main() does just that in nearly every C++ program. Functions can even call themselves, which is discussed soon, in the section on recursion.
Although there is no limit to the size of a function in C++, well-designed functions tend to be small. Many programmers advise keeping your functions short enough to fit on a single screen so that you can see the entire function at one time. This is a rule of thumb, often broken by very good programmers, but a smaller function is easier to understand and maintain.
Each function should carry out a single, easily understood task. If your functions start getting large, look for places where you can divide them into component tasks.
Function arguments do not have to all be of the same type. It is perfectly reasonable to write a function that takes an integer, two longs, and a character as its arguments.
Any valid C++ expression can be a function argument, including constants, mathematical and logical expressions, and other functions that return a value.
Although it is legal for one function to take as a parameter a second function that returns a value, it can make for code that is hard to read and hard to debug.
As an example, say you have the functions double(), triple(), square(), and cube(), each of which returns a value. You could write
Answer = (double(triple(square(cube(myValue)))));
This statement takes a variable, myValue, and passes it as an argument to the function cube(), whose return value is passed as an argument to the function square(), whose return value is in turn passed to triple(), and that return value is passed to double(). The return value of this doubled, tripled, squared, and cubed number is now passed to Answer.
It is difficult to be certain what this code does (was the value tripled before or after it was squared?), and if the answer is wrong it will be hard to figure out which function failed.
An alternative is to assign each step to its own intermediate variable:
unsigned long myValue = 2; unsigned long cubed = cube(myValue); // cubed = 8 unsigned long squared = square(cubed); // squared = 64 unsigned long tripled = triple(squared); // tripled = 196 unsigned long Answer = double(tripled); // Answer = 392
Now each intermediate result can be examined, and the order of execution is explicit.
The arguments passed in to the function are local to the function. Changes made to the arguments do not affect the values in the calling function. This is known as passing by value, which means a local copy of each argument is made in the function. These local copies are treated just like any other local variables. Listing 5.5 illustrates this point.
Listing 5.5. A demonstration of passing by value.
1: // Listing 5.5 - demonstrates passing by value
2:
3: #include <iostream.h>
4:
5: void swap(int x, int y);
6:
7: int main()
8: {
9: int x = 5, y = 10;
10:
11: cout << "Main. Before swap, x: " << x << " y: " << y << "\n";
12: swap(x,y);
13: cout << "Main. After swap, x: " << x << " y: " << y << "\n";
14: return 0;
15: }
16:
17: void swap (int x, int y)
18: {
19: int temp;
20:
21: cout << "Swap. Before swap, x: " << x << " y: " << y << "\n";
22:
23: temp = x;
24: x = y;
25: y = temp;
26:
27: cout << "Swap. After swap, x: " << x << " y: " << y << "\n";
28:
29: }
Output: Main. Before swap, x: 5 y: 10
Swap. Before swap, x: 5 y: 10
Swap. After swap, x: 10 y: 5
Main. After swap, x: 5 y: 10
Analysis: This program initializes two variables
in main() and then passes them to the swap() function, which appears
to swap them. When they are examined again in main(), however, they are
unchanged!
The variables are initialized on line 9, and their values are displayed on line 11.
swap() is called, and the variables are passed in.
Execution of the program switches to the swap() function, where on line 21 the values are printed again. They are in the same order as they were in main(), as expected. On lines 23 to 25 the values are swapped, and this action is confirmed by the printout on line 27. Indeed, while in the swap() function, the values are swapped.
Execution then returns to line 13, back in main(), where the values are no longer swapped.
As you've figured out, the values passed in to the swap() function are passed by value, meaning that copies of the values are made that are local to swap(). These local variables are swapped in lines 23 to 25, but the variables back in main() are unaffected.
On Days 8 and 10 you'll see alternatives to passing by value that will allow the values in main() to be changed.
Functions return a value or return void. Void is a signal to the compiler that no value will be returned.
To return a value from a function, write the keyword return followed by the value you want to return. The value might itself be an expression that returns a value. For example:
return 5; return (x > 5); return (MyFunction());
These are all legal return statements, assuming that the function MyFunction() itself returns a value. The value in the second statement, return (x > 5), will be zero if x is not greater than 5, or it will be 1. What is returned is the value of the expression, 0 (false) or 1 (true), not the value of x.
When the return keyword is encountered, the expression following return is returned as the value of the function. Program execution returns immediately to the calling function, and any statements following the return are not executed.
It is legal to have more than one return statement in a single function. Listing 5.6 illustrates this idea.
Listing 5.6. A demonstration of multiple return statements.
1: // Listing 5.6 - demonstrates multiple return
2: // statements
3:
4: #include <iostream.h>
5:
6: int Doubler(int AmountToDouble);
7:
8: int main()
9: {
10:
11: int result = 0;
12: int input;
13:
14: cout << "Enter a number between 0 and 10,000 to double: ";
15: cin >> input;
16:
17: cout << "\nBefore doubler is called... ";
18: cout << "\ninput: " << input << " doubled: " << result << "\n";
19:
20: result = Doubler(input);
21:
22: cout << "\nBack from Doubler...\n";
23: cout << "\ninput: " << input << " doubled: " << result << "\n";
24:
25:
26: return 0;
27: }
28:
29: int Doubler(int original)
30: {
31: if (original <= 10000)
32: return original * 2;
33: else
34: return -1;
35: cout << "You can't get here!\n";
36: }
Output: Enter a number between 0 and 10,000 to double: 9000
Before doubler is called...
input: 9000 doubled: 0
Back from doubler...
input: 9000 doubled: 18000
Enter a number between 0 and 10,000 to double: 11000
Before doubler is called...
input: 11000 doubled: 0
Back from doubler...
input: 11000 doubled: -1
Analysis: A number is requested on lines 14
and 15, and printed on line 18, along with the local variable result. The function
Doubler() is called on line 20, and the input value is passed as a parameter.
The result will be assigned to the local variable result, and the values
will be reprinted on lines 22 and 23.
On line 31, in the function Doubler(), the parameter is tested to see whether
it is greater than 10,000. If it is not, the function returns twice the original
number. If it is greater than 10,000, the function returns -1 as an error
value.
The statement on line 35 is never reached, because whether or not the value is greater than 10,000, the function returns before it gets to line 35, on either line 32 or line 34. A good compiler will warn that this statement cannot be executed, and a good programmer will take it out!
For every parameter you declare in a function prototype and definition, the calling function must pass in a value. The value passed in must be of the declared type. Thus, if you have a function declared as
long myFunction(int);
the function must in fact take an integer variable. If the function definition differs, or if you fail to pass in an integer, you will get a compiler error.
The one exception to this rule is if the function prototype declares a default value for the parameter. A default value is a value to use if none is supplied. The preceding declaration could be rewritten as
long myFunction (int x = 50);
This prototype says, "myFunction() returns a long and takes an integer parameter. If an argument is not supplied, use the default value of 50." Because parameter names are not required in function prototypes, this declaration could have been written as
long myFunction (int = 50);
The function definition is not changed by declaring a default parameter. The function definition header for this function would be
long myFunction (int x)
If the calling function did not include a parameter, the compiler would fill x with the default value of 50. The name of the default parameter in the prototype need not be the same as the name in the function header; the default value is assigned by position, not name.
Any or all of the function's parameters can be assigned default values. The one restriction is this: If any of the parameters does not have a default value, no previous parameter may have a default value.
If the function prototype looks like
long myFunction (int Param1, int Param2, int Param3);
you can assign a default value to Param2 only if you have assigned a default value to Param3. You can assign a default value to Param1 only if you've assigned default values to both Param2 and Param3. Listing 5.7 demonstrates the use of default values.
Listing 5.7. A demonstration of default parameter values.
1: // Listing 5.7 - demonstrates use
2: // of default parameter values
3:
4: #include <iostream.h>
5:
6: int AreaCube(int length, int width = 25, int height = 1);
7:
8: int main()
9: {
10: int length = 100;
11: int width = 50;
12: int height = 2;
13: int area;
14:
15: area = AreaCube(length, width, height);
16: cout << "First area equals: " << area << "\n";
17:
18: area = AreaCube(length, width);
19: cout << "Second time area equals: " << area << "\n";
20:
21: area = AreaCube(length);
22: cout << "Third time area equals: " << area << "\n";
23: return 0;
24: }
25:
26: AreaCube(int length, int width, int height)
27: {
28:
29: return (length * width * height);
30: }
Output: First area equals: 10000 Second time area equals: 5000 Third time area equals: 2500
Analysis: On line 6, the AreaCube()
prototype specifies that the AreaCube() function takes three integer parameters.
The last two have default values.
This function computes the area of the cube whose dimensions are passed in. If no
width is passed in, a width of 25 is used and a height
of 1 is used. If the width but not the height is passed in, a height
of 1 is used. It is not possible to pass in the height without passing in
a width.
On lines 10-12, the dimensions length, height, and width are initialized, and they are passed to the AreaCube() function on line 15. The values are computed, and the result is printed on line 16.
Execution returns to line 18, where AreaCube() is called again, but with no value for height. The default value is used, and again the dimensions are computed and printed.
Execution returns to line 21, and this time neither the width nor the height is passed in. Execution branches for a third time to line 27. The default values are used. The area is computed and then printed.
DO remember that function parameters act as local variables within the function. DON'T try to create a default value for a first parameter if there is no default value for the second. DON'T forget that arguments passed by value can not affect the variables in the calling function. DON'T forget that changes to a global variable in one function change that variable for all functions.
C++ enables you to create more than one function with the same name. This is called function overloading. The functions must differ in their parameter list, with a different type of parameter, a different number of parameters, or both. Here's an example:
int myFunction (int, int); int myFunction (long, long); int myFunction (long);
myFunction() is overloaded with three different parameter lists. The first and second versions differ in the types of the parameters, and the third differs in the number of parameters.
The return types can be the same or different on overloaded functions. You should note that two functions with the same name and parameter list, but different return types, generate a compiler error.
Function polymorphism refers to the ability to "overload" a function with more than one meaning. By changing the number or type of the parameters, you can give two or more functions the same function name, and the right one will be called by matching the parameters used. This allows you to create a function that can average integers, doubles, and other values without having to create individual names for each function, such as AverageInts(), AverageDoubles(), and so on.
Suppose you write a function that doubles whatever input you give it. You would like to be able to pass in an int, a long, a float, or a double. Without function overloading, you would have to create four function names:
int DoubleInt(int); long DoubleLong(long); float DoubleFloat(float); double DoubleDouble(double);
With function overloading, you make this declaration:
int Double(int); long Double(long); float Double(float); double Double(double);
This is easier to read and easier to use. You don't have to worry about which one to call; you just pass in a variable, and the right function is called automatically. Listing 5.8 illustrates the use of function overloading.
Listing 5.8. A demonstration of function polymorphism.
1: // Listing 5.8 - demonstrates
2: // function polymorphism
3:
4: #include <iostream.h>
5:
6: int Double(int);
7: long Double(long);
8: float Double(float);
9: double Double(double);
10:
11: int main()
12: {
13: int myInt = 6500;
14: long myLong = 65000;
15: float myFloat = 6.5F;
16: double myDouble = 6.5e20;
17:
18: int doubledInt;
19: long doubledLong;
20: float doubledFloat;
21: double doubledDouble;
22:
23: cout << "myInt: " << myInt << "\n";
24: cout << "myLong: " << myLong << "\n";
25: cout << "myFloat: " << myFloat << "\n";
26: cout << "myDouble: " << myDouble << "\n";
27:
28: doubledInt = Double(myInt);
29: doubledLong = Double(myLong);
30: doubledFloat = Double(myFloat);
31: doubledDouble = Double(myDouble);
32:
33: cout << "doubledInt: " << doubledInt << "\n";
34: cout << "doubledLong: " << doubledLong << "\n";
35: cout << "doubledFloat: " << doubledFloat << "\n";
36: cout << "doubledDouble: " << doubledDouble << "\n";
37:
38: return 0;
39: }
40:
41: int Double(int original)
42: {
43: cout << "In Double(int)\n";
44: return 2 * original;
45: }
46:
47: long Double(long original)
48: {
49: cout << "In Double(long)\n";
50: return 2 * original;
51: }
52:
53: float Double(float original)
54: {
55: cout << "In Double(float)\n";
56: return 2 * original;
57: }
58:
59: double Double(double original)
60: {
61: cout << "In Double(double)\n";
62: return 2 * original;
63: }
Output: myInt: 6500 myLong: 65000 myFloat: 6.5 myDouble: 6.5e+20 In Double(int) In Double(long) In Double(float) In Double(double) DoubledInt: 13000 DoubledLong: 130000 DoubledFloat: 13 DoubledDouble: 1.3e+21
Analysis: The Double()function
is overloaded with int, long, float, and double.
The prototypes are on lines 6-9, and the definitions are on lines 41-63.
In the body of the main program, eight local variables are declared. On lines 13-16,
four of the values are initialized, and on lines 28-31, the other four are assigned
the results of passing the first four to the Double() function. Note that
when Double() is called, the calling function does not distinguish which
one to call; it just passes in an argument, and the correct one is invoked.
The compiler examines the arguments and chooses which of the four Double() functions to call. The output reveals that each of the four was called in turn, as you would expect.
Because functions are so central to programming, a few special topics arise which might be of interest when you confront unusual problems. Used wisely, inline functions can help you squeak out that last bit of performance. Function recursion is one of those wonderful, esoteric bits of programming which, every once in a while, can cut through a thorny problem otherwise not easily solved.
When you define a function, normally the compiler creates just one set of instructions in memory. When you call the function, execution of the program jumps to those instructions, and when the function returns, execution jumps back to the next line in the calling function. If you call the function 10 times, your program jumps to the same set of instructions each time. This means there is only one copy of the function, not 10.
There is some performance overhead in jumping in and out of functions. It turns out that some functions are very small, just a line or two of code, and some efficiency can be gained if the program can avoid making these jumps just to execute one or two instructions. When programmers speak of efficiency, they usually mean speed: the program runs faster if the function call can be avoided.
If a function is declared with the keyword inline, the compiler does not create a real function: it copies the code from the inline function directly into the calling function. No jump is made; it is just as if you had written the statements of the function right into the calling function.
Note that inline functions can bring a heavy cost. If the function is called 10 times, the inline code is copied into the calling functions each of those 10 times. The tiny improvement in speed you might achieve is more than swamped by the increase in size of the executable program. Even the speed increase might be illusory. First, today's optimizing compilers do a terrific job on their own, and there is almost never a big gain from declaring a function inline. More important, the increased size brings its own performance cost.
What's the rule of thumb? If you have a small function, one or two statements, it is a candidate for inline. When in doubt, though, leave it out. Listing 5.9 demonstrates an inline function.
Listing 5.9. Demonstrates an inline function.
1: // Listing 5.9 - demonstrates inline functions
2:
3: #include <iostream.h>
4:
5: inline int Double(int);
6:
7: int main()
8: {
9: int target;
10:
11: cout << "Enter a number to work with: ";
12: cin >> target;
13: cout << "\n";
14:
15: target = Double(target);
16: cout << "Target: " << target << endl;
17:
18: target = Double(target);
19: cout << "Target: " << target << endl;
20:
21:
22: target = Double(target);
23: cout << "Target: " << target << endl;
24: return 0;
25: }
26:
27: int Double(int target)
28: {
29: return 2*target;
30: }
Output: Enter a number to work with: 20
Target: 40
Target: 80
Target: 160
This compiles into code that is the same as if you had written the following:
target = 2 * target;
everywhere you entered
target = Double(target);
By the time your program executes, the instructions are already in place, compiled into the OBJ file. This saves a jump in the execution of the code, at the cost of a larger program.
NOTE: Inline is a hint to the compiler that you would like the function to be inlined. The compiler is free to ignore the hint and make a real function call.
A function can call itself. This is called recursion, and recursion can be direct or indirect. It is direct when a function calls itself; it is indirect recursion when a function calls another function that then calls the first function.
Some problems are most easily solved by recursion, usually those in which you act on data and then act in the same way on the result. Both types of recursion, direct and indirect, come in two varieties: those that eventually end and produce an answer, and those that never end and produce a runtime failure. Programmers think that the latter is quite funny (when it happens to someone else).
It is important to note that when a function calls itself, a new copy of that function is run. The local variables in the second version are independent of the local variables in the first, and they cannot affect one another directly, any more than the local variables in main() can affect the local variables in any function it calls, as was illustrated in Listing 5.4.
To illustrate solving a problem using recursion, consider the Fibonacci series:
1,1,2,3,5,8,13,21,34...
Each number, after the second, is the sum of the two numbers before it. A Fibonacci problem might be to determine what the 12th number in the series is.
One way to solve this problem is to examine the series carefully. The first two numbers are 1. Each subsequent number is the sum of the previous two numbers. Thus, the seventh number is the sum of the sixth and fifth numbers. More generally, the nth number is the sum of n - 2 and n - 1, as long as n > 2.
Recursive functions need a stop condition. Something must happen to cause the program to stop recursing, or it will never end. In the Fibonacci series, n < 3 is a stop condition.
The algorithm to use is this:
If you call fib(1), it returns 1. If you call fib(2), it returns 1. If you call fib(3), it returns the sum of calling fib(2) and fib(1). Because fib(2) returns 1 and fib(1) returns 1, fib(3) will return 2.
If you call fib(4), it returns the sum of calling fib(3) and fib(2). We've established that fib(3) returns 2 (by calling fib(2) and fib(1)) and that fib(2) returns 1, so fib(4) will sum these numbers and return 3, which is the fourth number in the series.
Taking this one more step, if you call fib(5), it will return the sum of fib(4) and fib(3). We've established that fib(4) returns 3 and fib(3) returns 2, so the sum returned will be 5.
This method is not the most efficient way to solve this problem (in fib(20) the fib() function is called 13,529 times!), but it does work. Be careful: if you feed in too large a number, you'll run out of memory. Every time fib() is called, memory is set aside. When it returns, memory is freed. With recursion, memory continues to be set aside before it is freed, and this system can eat memory very quickly. Listing 5.10 implements the fib() function.
WARNING: When you run Listing 5.10, use a small number (less than 15). Because this uses recursion, it can consume a lot of memory.
Listing 5.10. Demonstrates recursion using the Fibonacci series.
1: // Listing 5.10 - demonstrates recursion
2: // Fibonacci find.
3: // Finds the nth Fibonacci number
4: // Uses this algorithm: Fib(n) = fib(n-1) + fib(n-2)
5: // Stop conditions: n = 2 || n = 1
6:
7: #include <iostream.h>
8:
9: int fib(int n);
10:
11: int main()
12: {
13:
14: int n, answer;
15: cout << "Enter number to find: ";
16: cin >> n;
17:
18: cout << "\n\n";
19:
20: answer = fib(n);
21:
22: cout << answer << " is the " << n << "th Fibonacci number\n";
23: return 0;
24: }
25:
26: int fib (int n)
27: {
28: cout << "Processing fib(" << n << ")... ";
29:
30: if (n < 3 )
31: {
32: cout << "Return 1!\n";
33: return (1);
34: }
35: else
36: {
37: cout << "Call fib(" << n-2 << ") and fib(" << n-1 << ").\n";
38: return( fib(n-2) + fib(n-1));
39: }
40: }
Output: Enter number to find: 5
Processing fib(5)... Call fib(3) and fib(4).
Processing fib(3)... Call fib(1) and fib(2).
Processing fib(1)... Return 1!
Processing fib(2)... Return 1!
Processing fib(4)... Call fib(2) and fib(3).
Processing fib(2)... Return 1!
Processing fib(3)... Call fib(1) and fib(2).
Processing fib(1)... Return 1!
Processing fib(2)... Return 1!
5 is the 5th Fibonacci number
Analysis: The program asks for a number
to find on line 15 and assigns that number to target. It then calls fib()
with the target. Execution branches to the fib() function, where,
on line 28, it prints its argument.
The argument n is tested to see whether it equals 1 or 2
on line 30; if so, fib() returns. Otherwise, it returns the sums of the
values returned by calling fib() on n-2 and n-1.
In the example, n is 5 so fib(5) is called from main(). Execution jumps to the fib() function, and n is tested for a value less than 3 on line 30. The test fails, so fib(5) returns the sum of the values returned by fib(3) and fib(4). That is, fib() is called on n-2 (5 - 2 = 3) and n-1 (5 - 1 = 4). fib(4) will return 3 and fib(3) will return 2, so the final answer will be 5.
Because fib(4) passes in an argument that is not less than 3, fib() will be called again, this time with 3 and 2. fib(3) will in turn call fib(2) and fib(1). Finally, the calls to fib(2) and fib(1) will both return 1, because these are the stop conditions.
The output traces these calls and the return values. Compile, link, and run this
program, entering first 1, then 2, then 3, building up to 6, and watch the output
carefully. Then, just for fun, try the number 20. If you don't run out of memory,
it makes quite a show!
Recursion is not used often in C++ programming, but it can be a powerful and elegant
tool for certain needs.
NOTE: Recursion is a very tricky part of advanced programming. It is presented here because it can be very useful to understand the fundamentals of how it works, but don't worry too much if you don't fully understand all the details.
When you call a function, the code branches to the called function, parameters are passed in, and the body of the function is executed. When the function completes, a value is returned (unless the function returns void), and control returns to the calling function.
How is this task accomplished? How does the code know where to branch to? Where are the variables kept when they are passed in? What happens to variables that are declared in the body of the function? How is the return value passed back out? How does the code know where to resume?
Most introductory books don't try to answer these questions, but without understanding this information, you'll find that programming remains a fuzzy mystery. The explanation requires a brief tangent into a discussion of computer memory.
One of the principal hurdles for new programmers is grappling with the many layers of intellectual abstraction. Computers, of course, are just electronic machines. They don't know about windows and menus, they don't know about programs or instructions, and they don't even know about 1s and 0s. All that is really going on is that voltage is being measured at various places on an integrated circuit. Even this is an abstraction: electricity itself is just an intellectual concept, representing the behavior of subatomic particles.
Few programmers bother much with any level of detail below the idea of values in RAM. After all, you don't need to understand particle physics to drive a car, make toast, or hit a baseball, and you don't need to understand the electronics of a computer to program one.
You do need to understand how memory is organized, however. Without a reasonably strong mental picture of where your variables are when they are created, and how values are passed among functions, it will all remain an unmanageable mystery.
When you begin your program, your operating system (such as DOS or Microsoft Windows) sets up various areas of memory based on the requirements of your compiler. As a C++ programmer, you'll often be concerned with the global name space, the free store, the registers, the code space, and the stack.
Global variables are in global name space. We'll talk more about global name space and the free store in coming days, but for now we'll focus on the registers, code space, and stack.
Registers are a special area of memory built right into the Central Processing Unit (or CPU). They take care of internal housekeeping. A lot of what goes on in the registers is beyond the scope of this book, but what we are concerned about is the set of registers responsible for pointing, at any given moment, to the next line of code. We'll call these registers, together, the instruction pointer. It is the job of the instruction pointer to keep track of which line of code is to be executed next.
The code itself is in code space, which is that part of memory set aside to hold
the binary form of the instructions you created in your program. Each line of source
code is translated into a series of instructions, and each of these instructions
is at a particular address in memory. The instruction pointer has the address of
the next instruction to execute. Figure 5.4 illustrates this idea.
Figure
5.4.The instruction pointer.
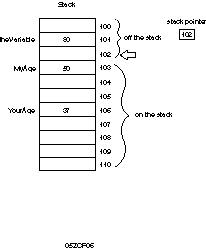
The stack is a special area of memory allocated for your program to hold the data
required by each of the functions in your program. It is called a stack because it
is a last-in, first-out queue, much like a stack of dishes at a cafeteria, as shown
in Figure 5.5.
Last-in, first-out means that whatever is added to the stack last will be the first thing taken off. Most queues are like a line at a theater: the first one on line is the first one off. A stack is more like a stack of coins: if you stack 10 pennies on a tabletop and then take some back, the last three you put on will be the first three you take off.
When data is "pushed" onto the stack, the stack grows; as data is "popped"
off the stack, the stack shrinks. It isn't possible to pop a dish off the stack without
first popping off all the dishes placed on after that dish.
Figure
5.5. A stack.
A stack of dishes is the common analogy. It is fine as far as it goes, but it is wrong in a fundamental way. A more accurate mental picture is of a series of cubbyholes aligned top to bottom. The top of the stack is whatever cubby the stack pointer (which is another register) happens to be pointing to.
Each of the cubbies has a sequential address, and one of those addresses is kept
in the stack pointer register. Everything below that magic address, known as the
top of the stack, is considered to be on the stack. Everything above the top of the
stack is considered to be off the stack and invalid. Figure 5.6 illustrates this
idea.
Figure
5.6.The stack pointer.
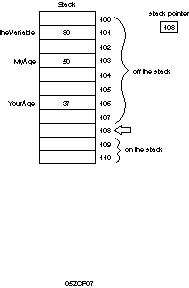
When data is put on the stack, it is placed into a cubby above the stack pointer,
and then the stack pointer is moved to the new data. When data is popped off the
stack, all that really happens is that the address of the stack pointer is changed
by moving it down the stack. Figure 5.7 makes this rule clear.
Figure
5.7. Moving the stack pointer.
Here's what happens when a program, running on a PC under DOS, branches to a function:
When the function is ready to return, the return value is placed in the area of the stack reserved at step 2. The stack is then popped all the way up to the stack frame pointer, which effectively throws away all the local variables and the arguments to the function.
The return value is popped off the stack and assigned as the value of the function call itself, and the address stashed away in step 1 is retrieved and put into the instruction pointer. The program thus resumes immediately after the function call, with the value of the function retrieved.
Some of the details of this process change from compiler to compiler, or between computers, but the essential ideas are consistent across environments. In general, when you call a function, the return address and the parameters are put on the stack. During the life of the function, local variables are added to the stack. When the function returns, these are all removed by popping the stack.
In coming days we'll look at other places in memory that are used to hold data that must persist beyond the life of the function.
This chapter introduced functions. A function is, in effect, a subprogram into which you can pass parameters and from which you can return a value. Every C++ program starts in the main() function, and main() in turn can call other functions.
A function is declared with a function prototype, which describes the return value, the function name, and its parameter types. A function can optionally be declared inline. A function prototype can also declare default variables for one or more of the parameters.
The function definition must match the function prototype in return type, name, and parameter list. Function names can be overloaded by changing the number or type of parameters; the compiler finds the right function based on the argument list.
Local function variables, and the arguments passed in to the function, are local to the block in which they are declared. Parameters passed by value are copies and cannot affect the value of variables in the calling function.
int Area (int width, int length = 1); int Area (int size);
The Workshop provides quiz questions to help you solidify your understanding of the material covered, and exercises to provide you with experience in using what you've learned. Try to answer the quiz and exercise questions before checking the answers in Appendix D, and make sure that you understand the answers before continuing to the next chapter.
#include <iostream.h>
void myFunc(unsigned short int x);
int main()
{
unsigned short int x, y;
y = myFunc(int);
cout << "x: " << x << " y: " << y << "\n";
}
void myFunc(unsigned short int x)
{
return (4*x);
}
#include <iostream.h>
int myFunc(unsigned short int x);
int main()
{
unsigned short int x, y;
y = myFunc(x);
cout << "x: " << x << " y: " << y << "\n";
}
int myFunc(unsigned short int x);
{
return (4*x);
}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}